Pseudo-Duplex Interaction for Text-Only LLMs
Overthinking Machines Lab builds more interactive LLM systems for the GPU poor. Here the target is narrow: take partial user input, estimate whether the user is still speaking, and prepare a useful reply before the user explicitly ends the turn.
Motivation
Most LLM interfaces are full-input-in, full-output-out. The user finishes a turn, sends it, waits, and receives a complete response. Human conversation is not like that. We hear partial utterances, track pauses, predict likely continuations, and often know when a turn is ending before the last word is fully processed.
Duplex speech models and richer interaction models attack this problem directly. They are also harder to serve, tend to be more expensive, and often complicate long-context text workflows. We asked whether a useful part of this behavior can be moved into a standard text LLM with a normal chat-completions serving path.
Problem Setup
- Can a standard chat model produce a turn prediction and a response in one sequence?
- Can turn completion be optimized jointly with response quality under partial input?
- Can elapsed silence, represented as explicit tokens, improve this signal?
Modeling Task
We keep the same base interface (normal chat completion), and change only the target structure. For each partial user turn, the model must output:
<user_preemptive>[predicted remaining user text or empty]</user_preemptive>
<assistant_preemptive>[assistant continuation]</assistant_preemptive>An empty user segment means “no likely continuation”, and the system can treat this as turn complete. Non-empty user continuation means the model prefers waiting for more user content.
Time Representation
We inject a fixed micro-timing token in user input only:
<|silence|>. Each token maps to ~500ms of elapsed
pause after the current word boundary. The same lexical prefix therefore
appears with multiple temporal states.
user: i think we should <|silence|> <|silence|>
target: <user_preemptive>probably wait before answer</user_preemptive>
<assistant_preemptive>Let's hold until they finish.</assistant_preemptive>user: i think we should <|silence|> <|silence|> <|silence|>
target: <user_preemptive></user_preemptive>
<assistant_preemptive>I can pull up the options now.</assistant_preemptive>Dataset
We use real multi-turn voice transcripts with word timing metadata. Silence tokens are added only in user turns to preserve system and assistant speaker structure while preserving causality.
We augment each full session into many training states by truncating user turns at different points:
- mid-sentence and near punctuation boundaries
- just after short and long intra-turn gaps
- multiple positions in end-of-turn silence
The target always contains both the hidden user suffix and the eventual assistant reply for the full reconstructed user turn.
History:
User: did you get a chance to look at the run
Assistant: yes, the reward moved but the eval was noisy
Current user prefix:
yeah i think <|silence|> <|silence|>
Target:
<user_preemptive>that is still enough for the demo</user_preemptive>
<assistant_preemptive>Then we should show the curve and be explicit that it is preliminary.</assistant_preemptive>Training
We train in a Prime RL loop over this tagged objective. The trainer computes sequence loss on both tags and aligns reward with two goals:
1) recover the missing user continuation, 2) generate the assistant response for the true turn endpoint. Non-ideal tags (malformed or partial tag blocks) are scored down.
We use curriculum scheduling over example generation. Early training focuses on longer visible user text and short history. Later phases reduce visible prefix, increase silence-only variants, and increase conversation depth to test timing and turn prediction under uncertainty.
Inference
The demo simulates streamed input by sending a new request on each
completed word boundary and then repeatedly after 500ms with extra
<|silence|> context. This produces multiple
candidate outputs over the same partial user text.
Silence tokens are retained in model history but removed from rendered chat text to keep the interface readable.
Results
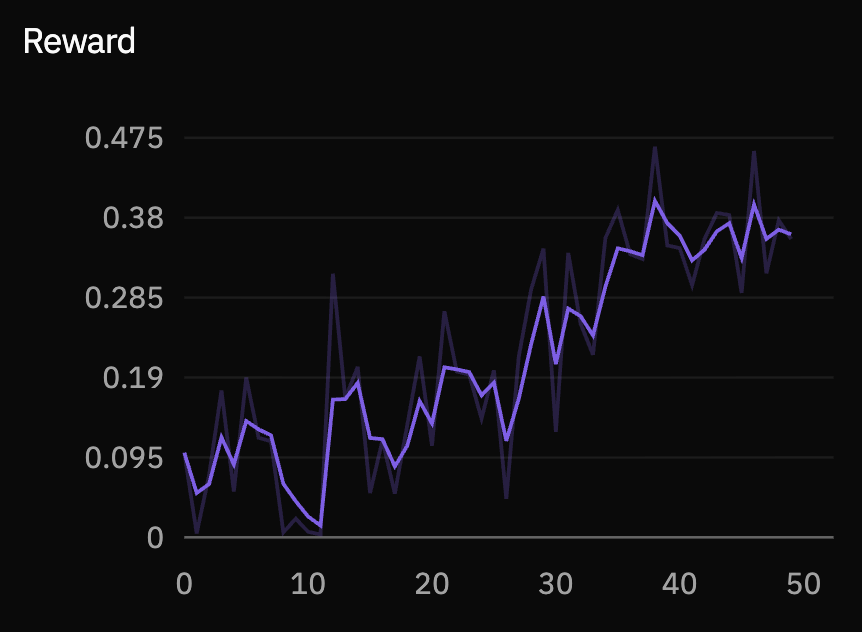
The first run is preliminary, but the training signal is clear. Reward rises over the run, format adherence becomes reliable, and the model improves on the specific behavior we care about most: predicting whether the user turn is over.
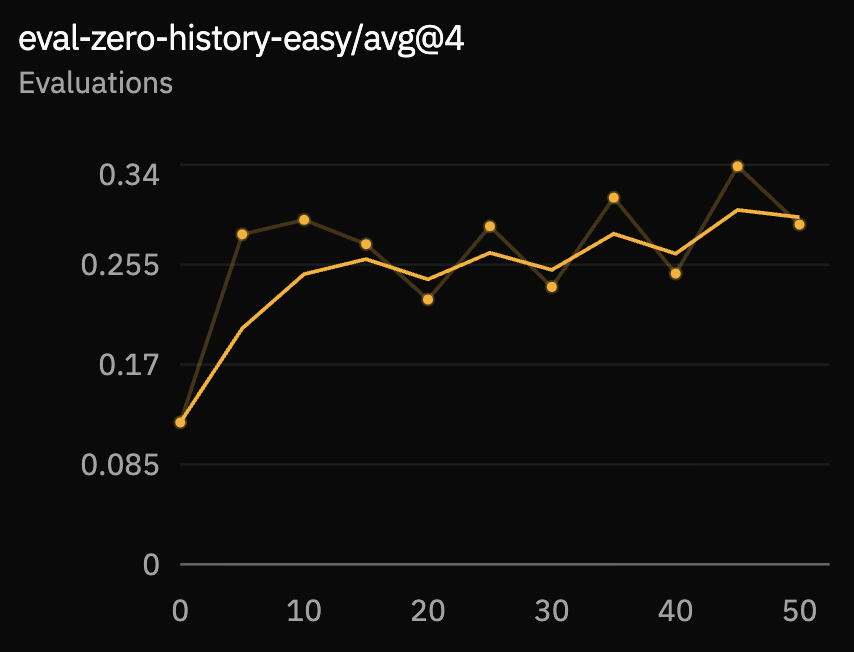
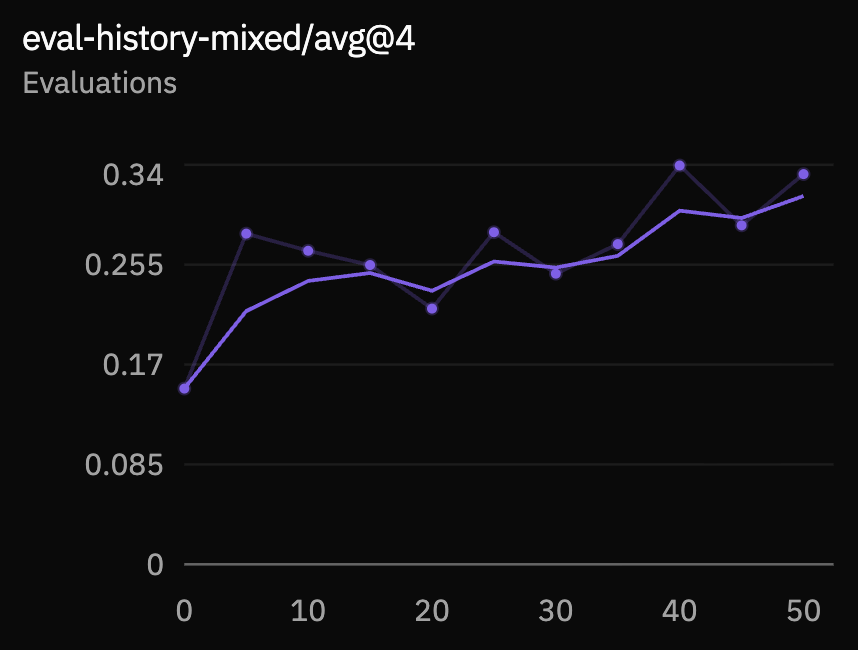
Response-quality metrics are noisier, as expected for a small conversational dataset with many acceptable replies. The stronger signal is structural: the model learns the tags, uses silence as part of the state, and improves turn-end prediction under both zero-history and mixed-history evaluation.
Training Objective
The aggregate reward combines format, user-continuation prediction, assistant response quality, and turn-boundary correctness. The curve is noisy because each step samples different partial-turn states, but the moving trend increases over the 50-step run.
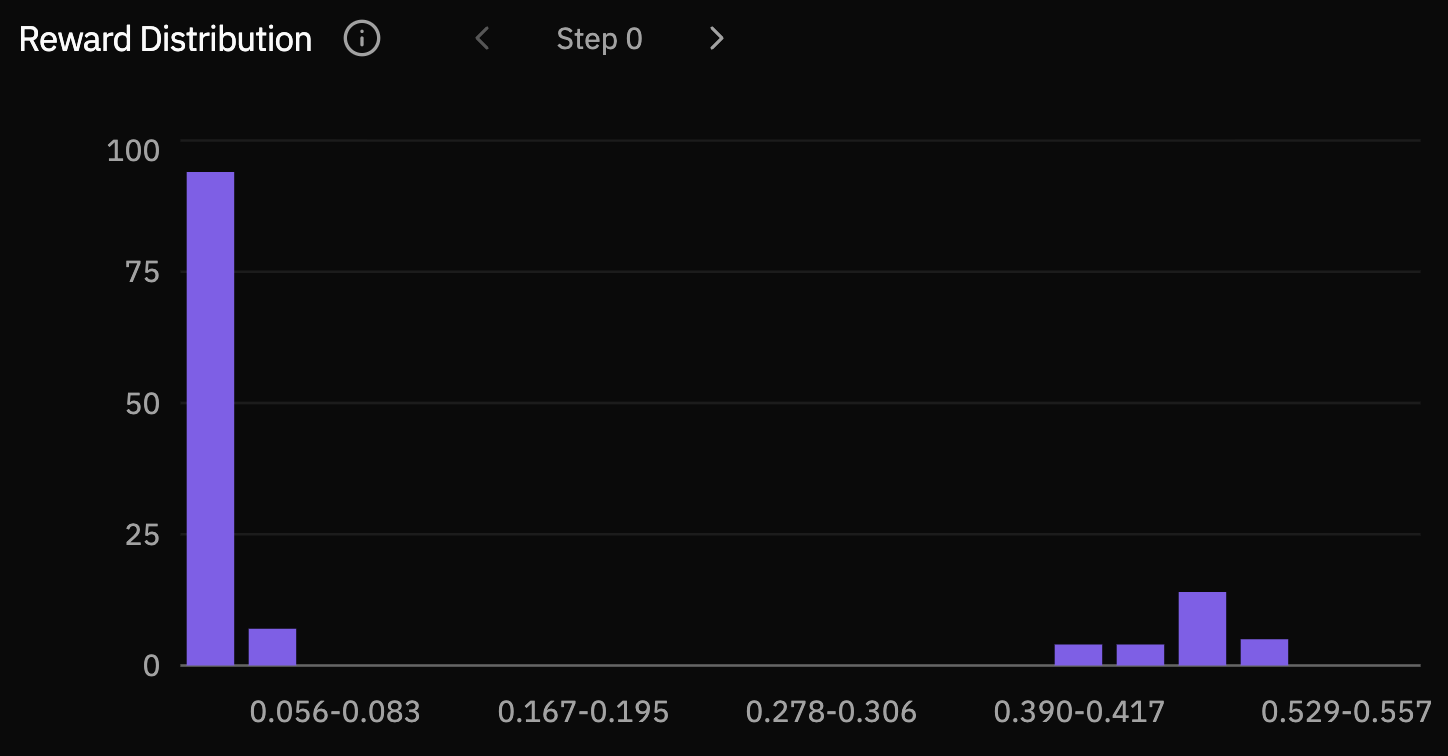
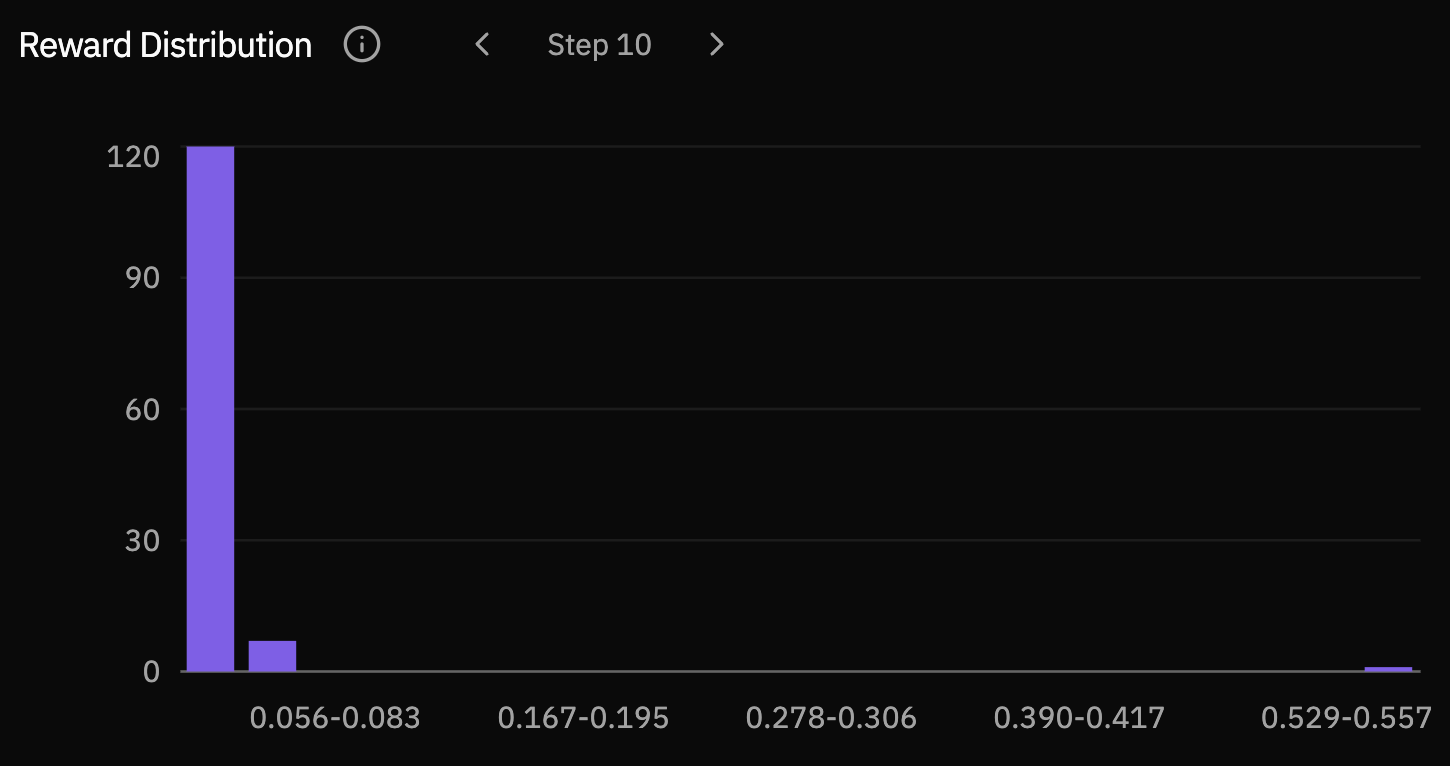
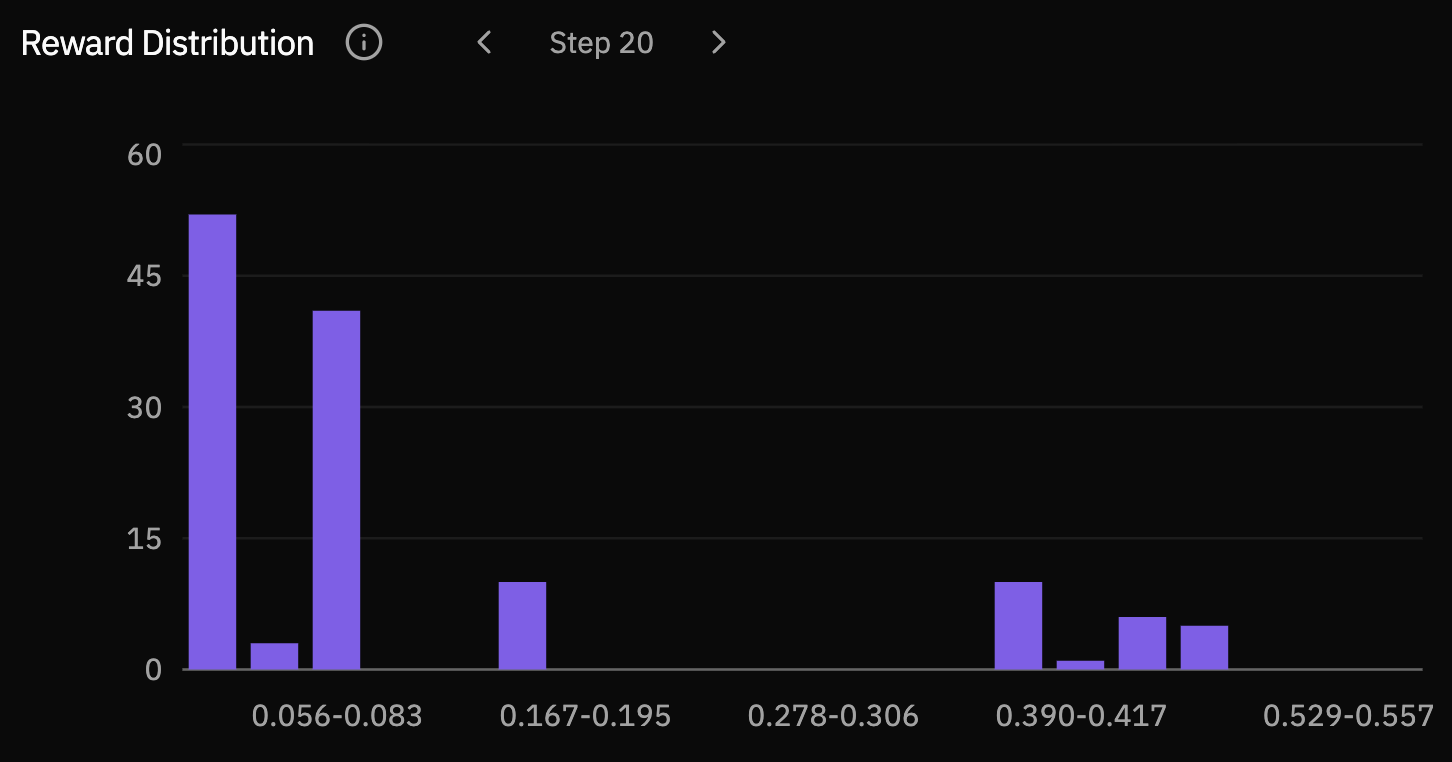
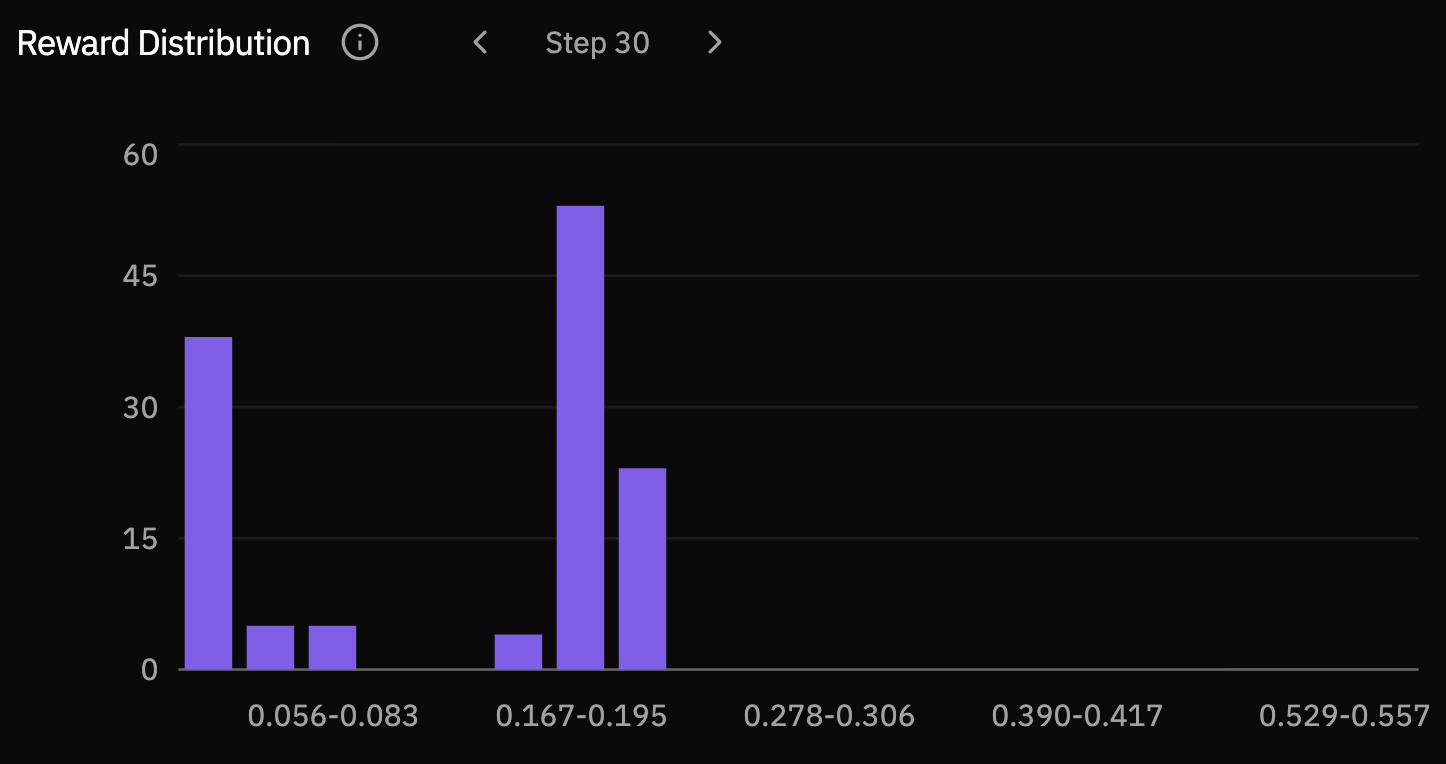
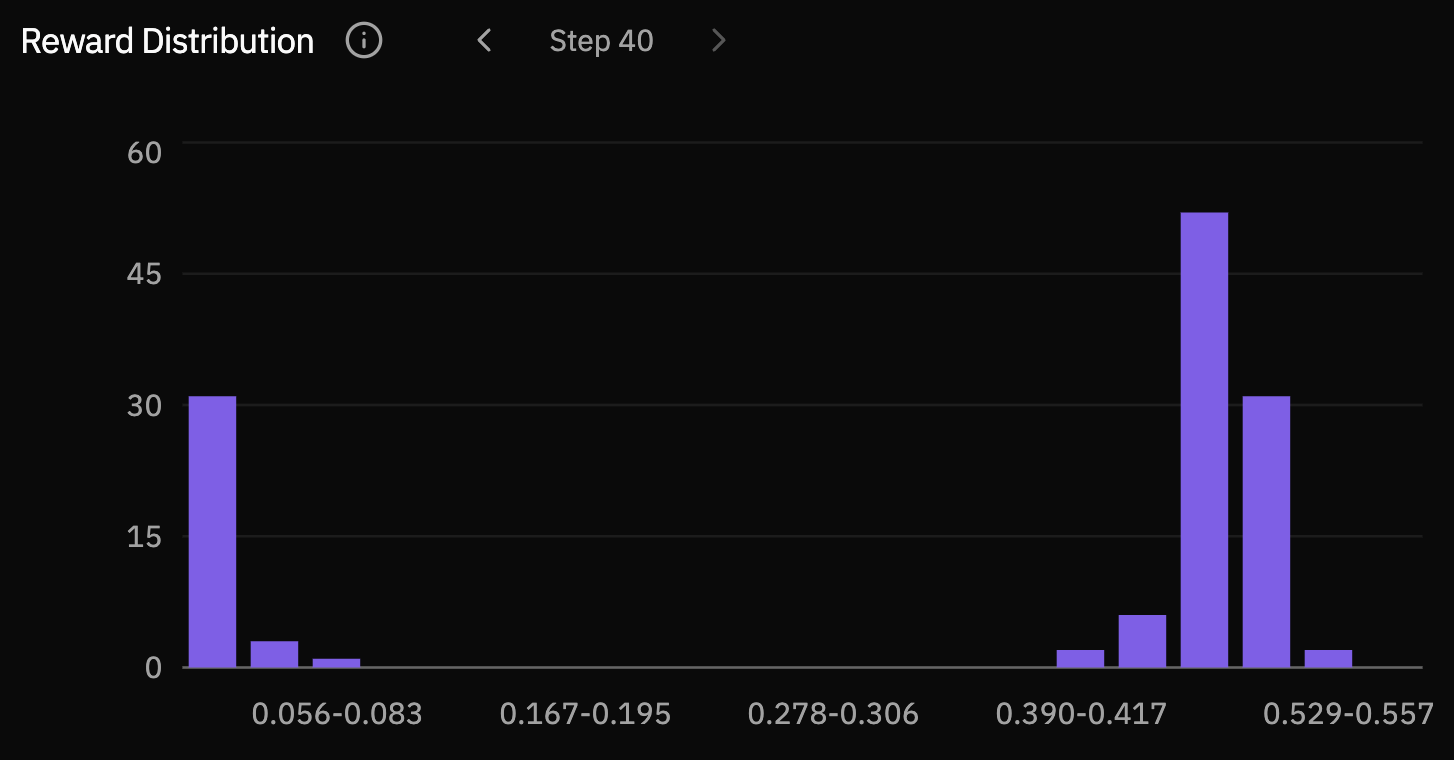
The reward distributions make the same movement easier to see. Early checkpoints place most rollouts in the lowest reward bucket. By steps 30 and 40, mass has shifted into the middle and high-reward buckets, showing that improvement is not only a few lucky samples.
Interaction Mechanics
These metrics test whether the model learned the interaction protocol,
not just generic response text. Format reward measures whether the
model emits the two required tags. Turn-end correctness measures
whether empty versus non-empty <user_preemptive>
matches the target wait/answer decision.
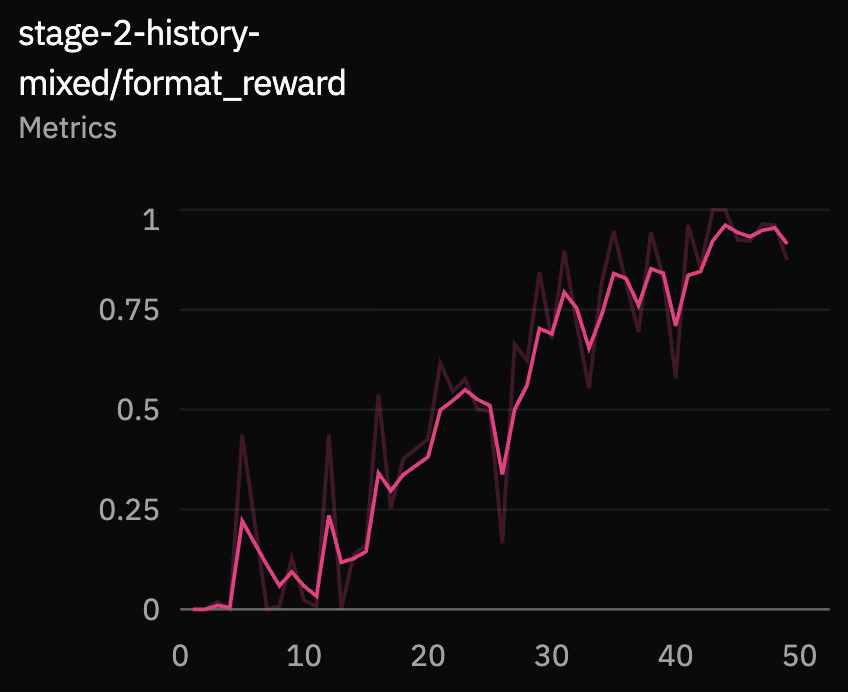
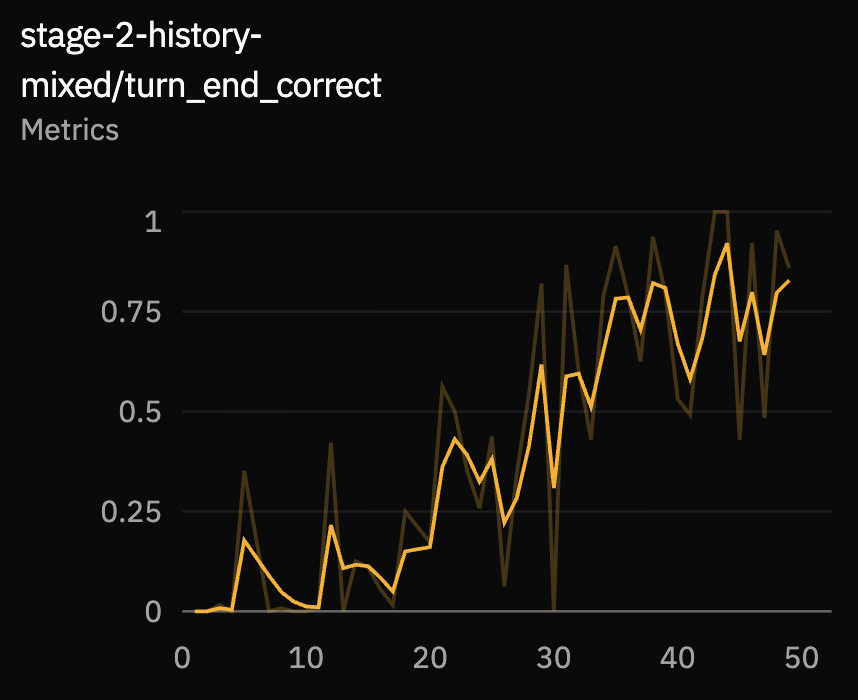
Prediction Quality
These metrics are harder to optimize exactly because spoken replies have many valid phrasings. User-completion similarity measures the predicted continuation of the unfinished user turn. Assistant response similarity and length similarity measure whether the eventual reply is semantically and structurally close to the target reply.
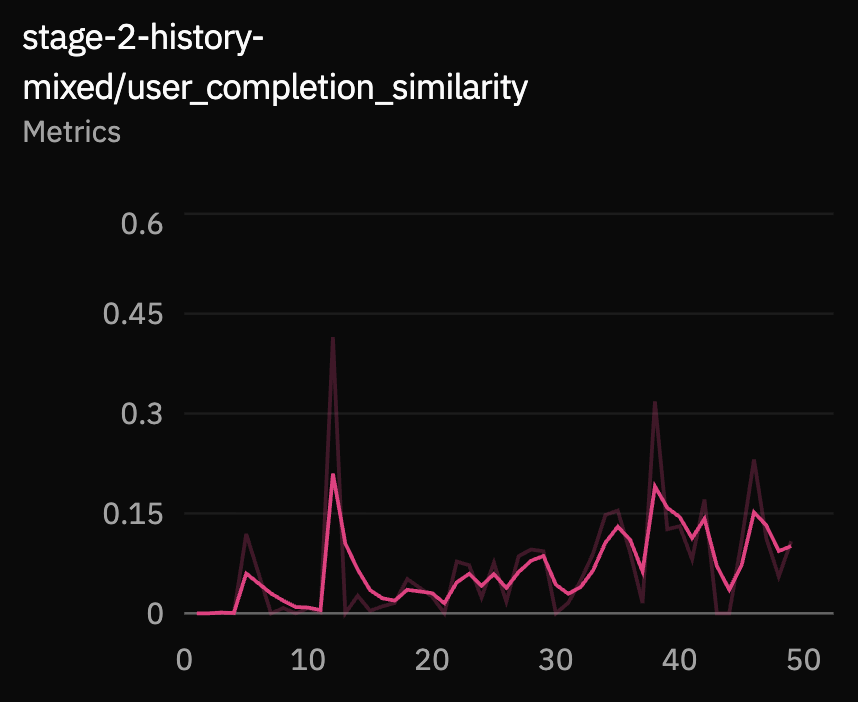
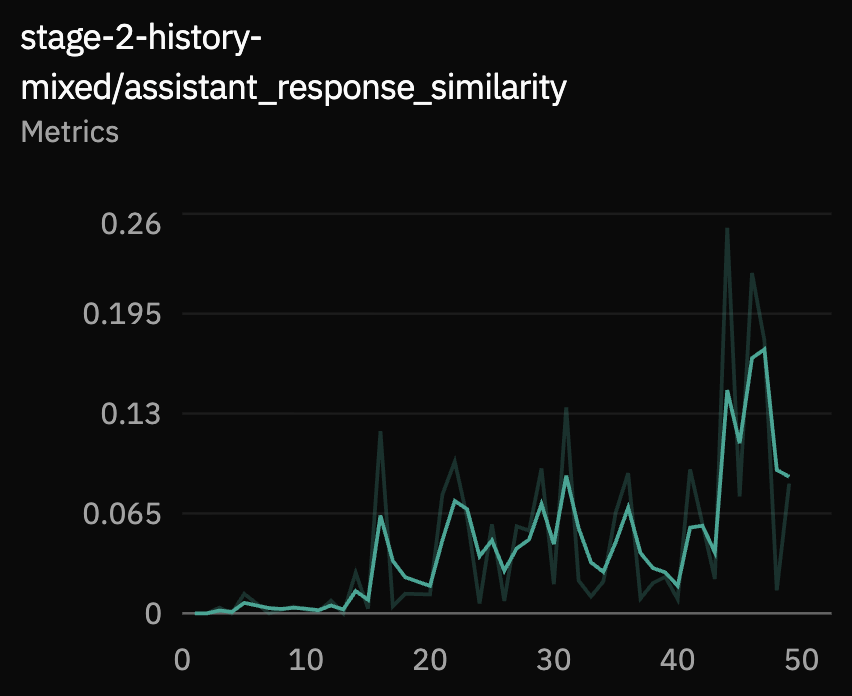
Held-Out Evaluations
We evaluate with four rollouts per example. The zero-history easy set isolates the base anticipatory task. The mixed-history set includes conversation history and is closer to the demo setting.